 Fraunhofer-Institut für Werkstoffmechanik IWM
Fraunhofer-Institut für Werkstoffmechanik IWMMaschinelles Lernen in der Werkstofftechnologie
Datengetriebene Methoden finden verstärkt Einzug in die Materialwissenschaften. Die Anwendungen reichen von Materialdesign über die Identifizierung versteckter Zusammenhänge (Data Mining) und Eigenschaftsvorhersage bis hin zur Charakterisierung von Mikrostrukturen, Defekten oder Schädigungen. Mittels solcher Methoden können, wegen ihrer hohen Repräsentationskraft und Wiedergabetreue, Vorhersagen gegenüber rein wissensbasierter Ansätze häufig stark verbessert werden. Dies trifft vor allem für viele Problemstellungen zu, für die das Domänenwissen und darauf basierende Modelle unvollständig sind.
Konventionelle Ansätze des maschinellen Lernens benötigen eine Vielzahl annotierter Trainingsdaten für das sogenannte überwachte Lernen. Entsprechende Methoden zeichnen sich beim Lernen durch eine geringe Dateneffizienz im Vergleich zum Menschen aus. Da der Datenannotationsprozess häufig nur durch Experten durchgeführt werden kann und entsprechend teuer ist, kann der hohe Bedarf für solche Methoden in den Materialwissenschaften nicht beliebig gestillt werden. Erschwerend kommt hinzu, dass viele Modelle eine schlechte Übertragbarkeit über Datensätze hinweg aufweisen. Konventionelle, überwacht trainierte Modelle weisen auch wegen spärlich besetzter Trainingsdatenräume, die großen Parameterräumen bei der Materialentwicklung gegenüberstehen, eine schlechte Generalisierbarkeit auf. Die Kombination genannter Charakteristika erschwert die Vorhersage für neue Materialien.
In der Gruppe Meso- und Mikromechanik beschäftigt sich ein Teilbereich damit, neuartige datengetriebene Ansätze für materialwissenschaftliche Fragestellungen zu qualifizieren und optimieren, um beide zuvor genannten Probleme zu adressieren.
Im Zuge der vergangenen Jahre wurden Methoden adaptiert, welche sich neben annotierten zusätzlich unannotierte Daten zunutze machen, um die Vorhersage gegenüber überwachten Lernmethoden deutlich zu verbessern – trotz Knappheit von annotierten Daten. Diese Methoden werden unter dem Begriff halbüberwachte Lernmethoden zusammengefasst. Unannotierte Daten können häufig ohne großen Mehraufwand dank des hohen Automatisierungsgrades industrieller Anlagen und analytischer Methoden gewonnen werden.
Den Aspekt der Übertragbarkeit zwischen Domänen adressieren wir mit Modellen, welche sich annotierte Daten aus einer Source-Domäne und unannotierte Daten aus einer verwandten Zieldomäne zu Nutze machen, um eine gute Vorhersagegüte in der Zieldomäne zu erreichen. Diese Aufgabenstellung wird als unsupervised domain adaptation bezeichnet. Als Source- und Ziel-Domänen können dabei unterschiedliche Prozessführung, Modalitäten, Materialien und Datenquellen (z. B. synthetisch/Simulationsdaten zu Experimentaldaten) fungieren.
Die erforderliche Datenmenge ist abhängig von der Komplexität der Architektur des neuronalen Netzes und der Problemstellung. Mittels intelligenter auf die Problemstellungen angepasster Strategien zur Daten Augmentation, können schon wenige zehn annotierte Bildinstanzen zum Trainieren von verhältnismäßig kompakten Netzwerken ausreichen.
Indem wir Kompetenzen aus der Materialwissenschaft und Informatik vereinen, trainieren wir maßgeschneiderte Modelle unter der Berücksichtigung relevanter Merkmale für Sie. Dabei können wir Sie bei der gesamten Prozesskette von der passenden Datenerhebung über die optimale Datenvorbereitung und Modellauswahl bis hin zu dessen Training, Evaluation und Deployment unterstützen.
- Beratung und/oder Unterstützung bei der Datenaufnahme
- Angemessene Vorbereitung (Skalierung, Normalisierung, Tiling, Registrierung, …) von Daten unter Berücksichtigung relevanter Merkmale und Modellcharakteristika sowie deren optimale Daten Augmentation
- Auswahl passender Daten für das Vortrainieren aus unserem internen Werkstoffdatenpool zur Verbesserung der Modelle trotz Datenknappheit
- Modellauswahl und –implementation
- Aufgabenstellungen zu Klassifikation, Segmentierung (Binär, Semantisch, Instanz, Panoptic) und Regression auf Pixeldaten, Voxeldaten, tabellarisch oder anhand von Graphen strukturierter Daten
- Überwachtes Training verschiedener (vortrainierter) Modelle auf leistungsstarker Hardware für schnellere Ergebnisse
- Halbüberwachtes Training unter zusätzlicher Zuhilfenahme unannotierter Daten für bessere Modelle im Fall geringer Datenquantität
- Un- oder halbüberwachte Domänenanpassung zwischen verwandten Materialien, Prozessierungen oder Modalitäten können helfen Ihre bestehenden Daten für neue Zielzustände zu verwerten ohne neue Daten zu annotieren.
- Modellevaluation und Robustheitsprüfung
Mikrostrukturquantifizierung von Komplexphasenstählen
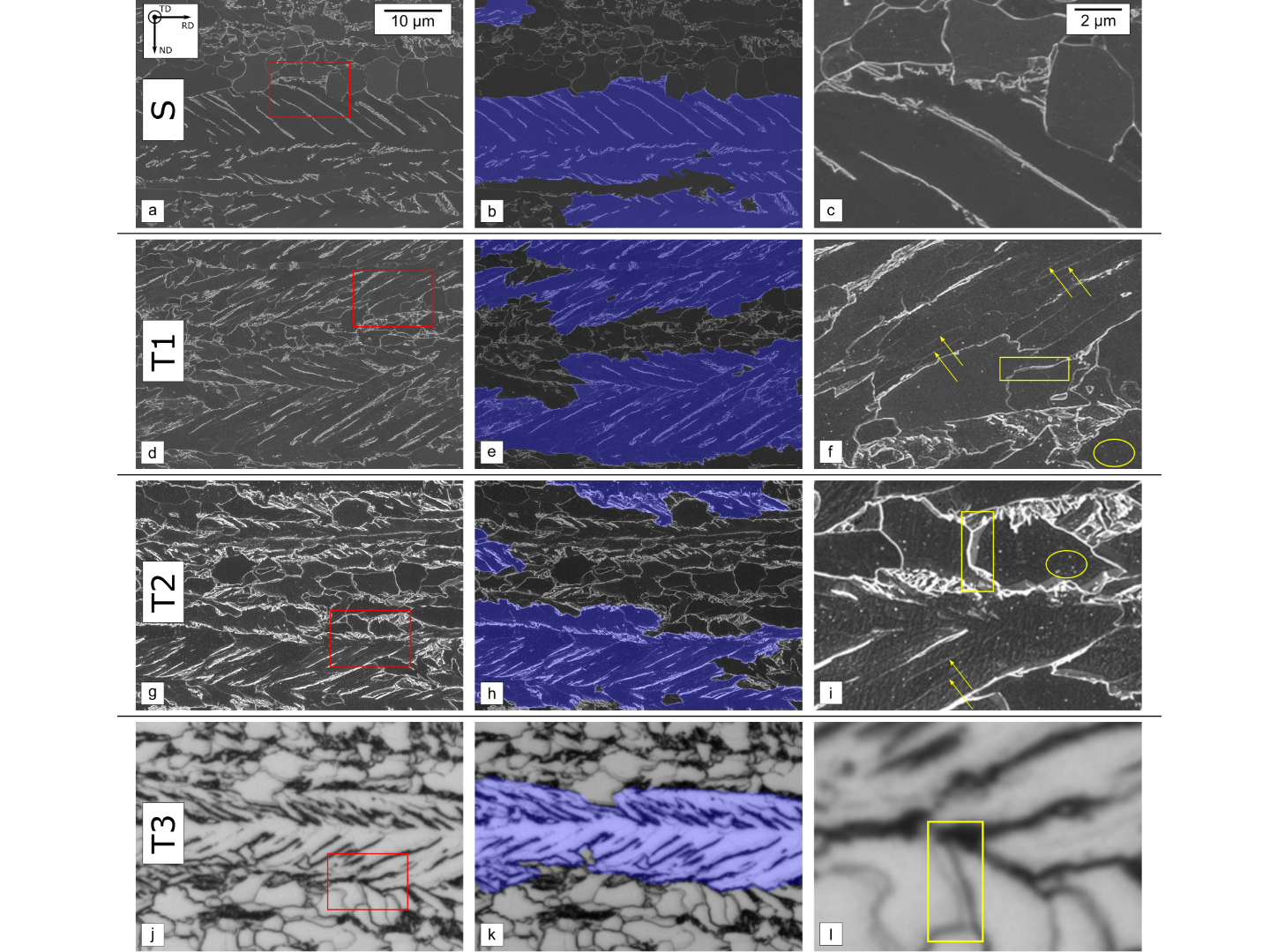
In zwei Kooperationen haben wir Modelle zur Bildsegmentierung entwickelt, welche lattenförmige Bainitbereiche in einem Komplexphasenstahl identifizieren können. Dazu wurden licht- und rasterelektronenmikroskopische Abbildungen angeätzter (kontrastierter) Oberflächen verwendet. Diese Aufgabenstellung kann von üblichen wissensbasierten Modellen nur mit einer vergleichsweise schlechten Vorhersagegüte behandelt werden. Um dieser komplizierten Fragestellung gerecht zu werden, nutzen wir faltungsbasierte neuronale Netze (engl. FCNN). Im Zuge zuvor genannter Forschungsarbeiten wurden systematisch Leitfaden für die Anwendung verschiedener Netze in Abhängigkeit der Daten erarbeitet. Dabei wurden Strategien zur Daten Augmentation abgeleitet, um Streuungen in den Daten optimal zu berücksichtigen. Des Weiteren wurde das Thema Interpretierbarkeit von FCNN-Modellen mit verschiedenen Visualisierungsmethoden behandelt, um das Vertrauen in den Modellen zu stärken und diese nach „unberechtigten“ Korrelationen zu untersuchen. Die überwacht trainierten Modelle haben auf den Testdaten Intersection over Union (IoU) Werte von etwa 80% (entspricht Genauigkeiten von etwa 90%) für verschiedene Modalitäten erzielt, siehe Abbildung 1.
Die IoU-Metrik ist zwischen 0 und 100% definiert und wird mittels der Anzahl an true positive, false positive und false negative Pixeln ermittelt:
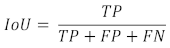
Diese Genauigkeiten entsprechen einer Segmentierungsqualität die durch Metallographen erreicht werden, bieten aber den Vorteil, dass auch komplizierte Gefüge automatisiert und reproduzierbar segmentiert werden können (mehr Informationen). Als überwacht trainierte Modelle auf eine andere Ätzung übertragen wurden, sind diese Modelle jedoch gescheitert.
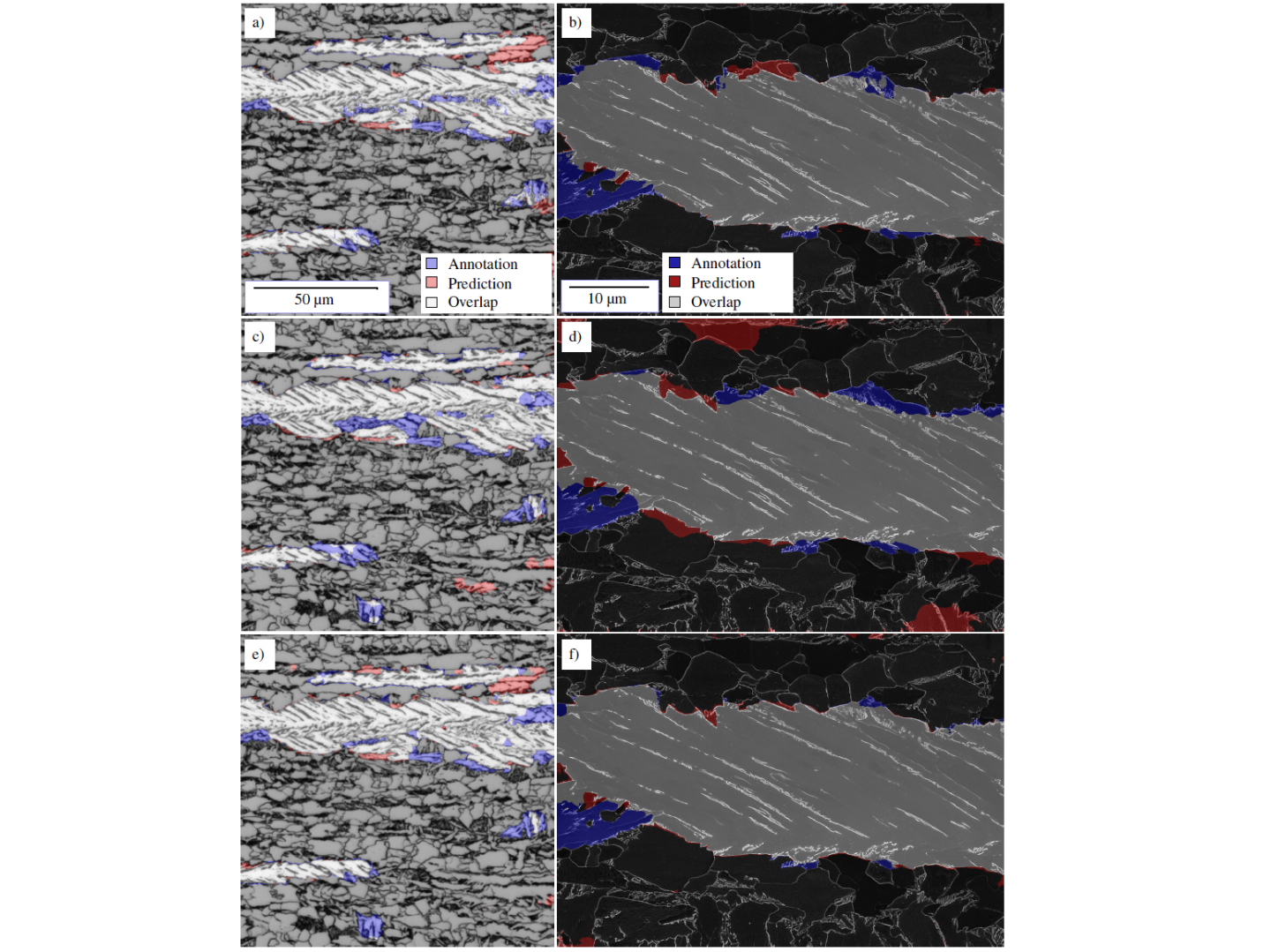
Um die schlechte Domänenübertragbarkeit vieler FCNN-Architekturen zu adressieren, wurde ein Framework zu unsupervised domain adaptation (UDA) erforscht. Diese Fragestellung beschäftigt sich mit dem Fall, dass für Zieldomänen keine annotierten Daten, sondern ausschließlich Eingangsdaten vorliegen aber trotzdem eine gute Segmentierung in der Zieldomäne erzielt werden soll. Als Zieldomänen wurden für diese Studie exemplarisch zwei verschiedene Ätzungen und lichtmikroskopische Abbildungen herangezogen (siehe Abbildung 2).
Durch UDA wurde die mittlere Intersection over Union (mIoU) gegenüber den Baseline-Modellen (überwacht auf der Source Domäne trainiert und auf Zieldomäne angewendet) jeweils von 82.2%, 61.0%, 49.7% auf 84.7% (+2,5%), 67.3% (+6,3%), 73.3% (+ 23,6%) verbessert für die drei Domänenübergänge. Der Vergleich zwischen Baseline-Modellen und UDA ist in Abbildungen 3-5 dargestellt.
Dies unterstreicht das Potential dieser Modelle, um datengetriebene Methoden zu entwickeln, die mit verschiedenen Domänenabständen gut umgehen können, und könnte den Annotationsbedarf erheblich reduzieren (mehr Informationen).



Bildsegmentierung von Materialschädigungen (Rissen und Extrusionen)


Eine weitere Fragestellung innerhalb der datengetriebenen Bildverarbeitung ist die Segmentierung von Ermüdungsschädigungen [1]. Die Beschaffenheit solcher Schädigungen hängt stark vom Material (Abbildung 6) und vom Belastungsszenario ab. Außerdem weisen Bilddaten von Schädigungen, aufgrund der optischen Abbildungseinstellungen, eine Streuung auf. Methoden des maschinellen Lernens erlauben die automatisierte Detektion solcher Schädigungsstellen in diversen Materialien. So kann mittels neuronalen Netzwerken, die bereits mit einem vielseitigen Datensatz trainiert wurden, eine pixelweise Riss- und Extrusionsdetektion (semantische Segmentierung) durchgeführt werden. Da der Trainingsdatensatz verschiedenste Riss und Extrusionsmorphologien (siehe Abbildung 6) wie beispielsweise Protrusionen 1) und lokalisierte zungenförmige Extrusionen 2) in mehreren Materialien enthält, wird von einer Übertragbarkeit auf weitere metallische Materialien ausgegangen. Diese automatisierte und generalisierende Methode verknüpfen wir mit automatisierter Rasterelektronenmikroskopie (REM), um eine effiziente Schädigungscharakterisierung an Proben- und Bauteiloberflächen zu gewährleisten. Bei der Schädigungsdetektion (Abbildung 7) in ferritischem Stahl EN 1.4003 wurde beispielsweise jeweils ein mittlerer IoU für Risse und Extrusionen von 0.84 und 0.71 erzielt. Eine solche Schädigungssegmentierung wurde beispielsweise dazu verwendet Kristallplatizitätssimulationen zum Kurzrisswachstum statistisch zu validieren [2].
[1] Thomas, A.; Durmaz, A. R.; Straub, T.; Eberl, C., Automated quantitative analyses of fatigue induced surface damage by deep learning, Materials 13/15 (2020) Art. 3298, 24 Seiten Link
[2] Natkowski, E.; Durmaz, A.R.; Sonnweber-Ribic, P.; Munstermann, S., Fatigue lifetime prediction with a validated micromechanical short crack model for the ferritic steel EN 1.4003, International Journal of Fatigue 152 (2021) Art. 106418; 15 Seiten
- Gublay, O.; Ackermann, M.; Gramlich, A.; Durmaz, A.R.; Krupp, U., Influence of transformation temperature on the high-cycle fatigue performance of carbide-bearing and carbide-free bainite, Steel Research International, Online first (2023) Art. 2300238, 14 Seiten Link
- Goetz, A.; Durmaz, A.R.; Müller, M.; Thomas, A.; Britz, D.; Kerfriden, P.; Eberl, C., Addressing materials’ microstructure diversity using transfer learning, npj Computational Materials 8 (2022) Art. 27; 13 Seiten Link
- Durmaz, A. R.; Müller, M.; Lei, B.; Thomas, A.; Britz, D.; Holm, E. A.; Eberl, C.; Mücklich, F.; Gumbsch, P., A deep learning approach for complex microstructure inference, Nature Communications 12/1 (2021) Art. 6272, 15 Seiten Link
- Natkowski, E.; Durmaz, A.R.; Sonnweber-Ribic, P.; Munstermann, S., Fatigue lifetime prediction with a validated micromechanical short crack model for the ferritic steel EN 1.4003, International Journal of Fatigue 152 (2021) Art. 106418; 15 Seiten Link
- Thomas, A.; Durmaz, A. R.; Straub, T.; Eberl, C., Automated quantitative analyses of fatigue induced surface damage by deep learning, Materials 13/15 (2020) Art. 3298, 24 Seiten Link