Expertengespräch: Dr. Michael Luke, Fraunhofer IWM: »Expertenwissen strukturieren«
Dr. Michael Luke leitet am Fraunhofer IWM das Geschäftsfeld Bauteilsicherheit und Leichtbau. Als Experte für Ermüdungsverhalten und Bruchmechanik von Metallen und Verbundwerkstoffen war er zuvor für das Deutsche Zentrum für Luft- und Raumfahrt und die Deutsche Bahn mit Werkstofffragen befasst. Wir sprachen mit ihm über die Potenziale der strukturierten Ablage von Materialdaten in der Produktentwicklung.
Herr Luke, Sie arbeiten an Datenräumen, mit denen man Produkte schneller entwickeln kann. Was ist denn überhaupt ein Datenraum?
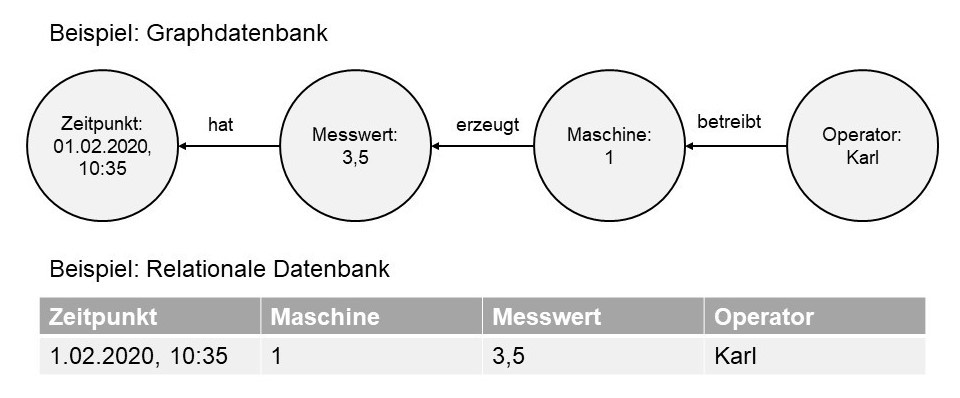
Das ist eine strukturierte Datenablage auf Basis von Ontologien. Das heißt, beliebige Informationen sind darin system-, fach- und Dimensionen übergreifend miteinander verknüpft. Jeder Datenpunkt in diesem Raum ist über die Wechselwirkungen mit anderen Datenpunkten und seine Historie identifizierbar.
Das klingt sehr virtuell. Was bedeutet das für die Produktentwicklung?
Technisch gesehen ist ein Datenraum nichts weiter als eine Datenbank. Der Clou ist aber, dass die Daten mit ihrer Entstehungsgeschichte und wichtigen Abhängigkeiten dort abgelegt sind, so dass man auf diesen Datenraum statistische oder Machine Learning Methoden anwenden kann, um eine verlässliche Vorhersage von Werkstoffsystemeigenschaften oder Vorschläge für optimale Werkstoffzustände zu bekommen. Ein sinnvoll angelegter und befüllter Werkstoff- oder Werkstoffsystemdatenraum ermöglicht einem Unternehmen belastbare Daten zur Vorhersage von Produkteigenschaften zu einem Zeitpunkt, in der die Hardware noch gar nicht da ist. So kann ich verschiedene Produktszenarien durchzuspielen, bevor ich mich für eines entscheide.
Das Implementieren von Datenräumen ist noch nicht in der Praxis angekommen. Warum nicht?
Es fehlen Erfahrungswerte und vorgefertigte Ontologien, auf denen man Produkten datentechnisch aufbauen kann. Eine akzeptierte Lösung zwischen unterschiedlichen Stakeholdern eines Unternehmens nimmt außerdem aufgrund der Abstimmung hinsichtlich Datensicherheit, Datensouveränität sowie neuer Geschäftsmodelle viel Zeit in Anspruch. Auch für einfache Anwendungsfälle muss man schon ein halbes Jahr für die Konzeption eines unternehmensspezifischen Datenraums einplanen. Die Fraunhofer-Gesellschaft hat daher Forschungsmittel bereitgestellt, um auf diesem Gebiet Vorarbeit für die deutsche Industrie zu leisten. Ziel ist es, ein Grundgerüst zu erarbeiten, das dann nur noch angepasst werden muss. Damit hält sich der Zusatzaufwand für Unternehmen in Grenzen.
Wie sieht das konkret aus, gibt es ein Forschungsprojekt?
So ist es. Drei Fraunhofer-Institute (IWM, IAIS, ITWM) haben sich zusammengeschlossen, um zu demonstrieren, welche Vorteile ein Unternehmen hat, wenn es Daten strukturiert ablegt und vernetzt und daher besser analysieren kann. Da alle Institute Teil der Fraunhofer-Gesellschaft sind, haben wir den Vorteil, dass wir rechtliche Fragestellungen beispielsweise zum Dateneigentum zunächst ausblenden können. Wir wollen der Industrie einen Demonstrator zur Verfügung zu stellen, mit dem wir zeigen, dass mit Ontologien strukturierte Daten wirklich einen geldwerten Vorteil in der digitalisierten Produktentwicklung darstellen. In diesem Demonstrator sollen die Datenräume unserer Anwendungsfälle in der gleichen Programmoberfläche nutzbar sein und kundentypische Fragen beantworten, beispielsweise »Wie muss mein Werkstoff eingestellt sein, wenn ich bestimmte Produkteigenschaften absichern will?«
Welche Anwendungsfälle untersucht das Projekt?
Wir betrachten in diesem Projekt zwei Anwendungsfälle und wollen zeigen, dass ein Datenraum jede Fragestellung erschlagen kann, wenn er richtig aufgesetzt ist.
Als Werkstoff betrachten wir höchstfeste Stähle, die zwar hohe Festigkeiten aufweisen, auf zyklische Belastung (Ermüdung) aber unter Umständen empfindlich reagieren. Bisher gibt es wenige Richtlinien, die verbindliche Aussagen zu ihrem Ermüdungsverhalten treffen, weil diese sich aus sehr vielen und gleichzeitig komplexen Faktoren ergeben, wie beispielsweise unterschiedliche Gefügen, Härten, Oberflächenrauheiten, Defektverteilungen, Wärmebehandlungszuständen und so weiter.
Als Werkstoffsystem betrachten wir Biege- und Torsionssteifigkeiten von Kabelbündeln für die Konfektionierung und Montagesimulation moderner Automobilelektronik. Die Kabel alleine bestehen schon aus unterschiedlich aufgebauten Metalllitzen und Kunststoffisolierungen. In Kabelbäumen kommen noch die unterschiedlichen geometrischen Anordnungen der Einzelkabel und deren Fixierung hinzu. Der Kabelbaum der zu einem Blinklicht geht, ist ein komplett anderer als der für die Antriebssteuerung. Alle resultierenden Biege- und Torsionssteifigkeiten messtechnisch zu ermitteln ist aufwändig, diese vorab aus bekannten Testdaten abzuleiten, die Zielstellung.
In beiden Fällen gilt es, alle relevanten Parameter und ihre Abhängigkeiten in der strukturierten Datenablage verfügbar zu haben. Dann können statistische und ML-Methoden die benötigten Antworten liefern.
Was sind die Herausforderungen bei der Implementierung eines Datenraumes?
Für die Unternehmen stellt sich die Frage, wie Daten aufbereitet sein müssen, damit sie erfasst werden können. Man kann nicht einfach direkt aus der Maschine Daten in eine Tabellenkalkulation laufen lassen. Damit die Daten übertragbar sind und eine Verknüpfung zwischen Herstellung und Prüfergebnis erlauben, sind standardisierte Begrifflichkeiten und Bezüge wichtig. In einer Ontologie kann es nur einen einheitlich definierten Begriff beispielsweise für die Festigkeit von Stählen geben. Das klingt jetzt viel trivialer als es tatsächlich ist – es reicht ja schon ein unterschiedlicher Buchstabe und ein ungeschultes Auge oder erst recht ein Computer erkennen es nicht als gleichwertig an. Im Projekt bauen wir auf der von der EU favorisierten EMMO (European Materials Modelling Ontology) auf, an deren Entwicklung wir maßgeblich beteiligt sind. Am Fraunhofer IWM nutzen wir in anderen Projekten allerdings auch die Basic Formal Ontology (BFO) des Briten Barry Smith.
Wenn wir ein Unternehmen begleiten, beginnen wir mit dem Zuhören. Der Kunde zeigt uns zu Beginn, wie er seine Dinge bezeichnet und wir analysieren dann gemeinsam die Bezüge zu einer Ontologie: Was kann wie eingespeist und abgelegt werden? Entscheidend ist, herauszufinden, welche Prozesse und Daten eigentlich wichtig sind. Manche Firmen haben ihre Not, wenn jahrzehntelange Erfahrungsträger aus dem Betrieb ausscheiden. Obwohl man die Abläufe unverändert fortsetzt, läuft es nicht mehr so wie vorher. Ein Grund ist vermutlich, dass der Experte unbewusst ein paar Daten im Kopf mitverfolgt hat, die in der Dokumentation nicht fixiert sind. Im Interview hinterfragen wir daher Arbeitsprozesse und helfen, Expertenwissen zu strukturieren und in einer anderen Form darzustellen.
Zum Glück sind sie Werkstoffexperten! Können Sie auch in anderen Domänen tätig werden?
Natürlich bieten wir unseren Kunden unser eigenes Domänenwissen, nicht nur im Bereich der Ontologieentwicklung, sondern in unseren klassischen werkstoffwissenschaftlichen Kernbereichen. Zu dem Zweck erzeugen wir auch Daten für den Datenraum des Kunden beispielsweise durch Ermüdungs- oder Crashexperimente. Darüber hinaus bieten wir Tools, die auf dem gefüllten Datenraum aufsetzen, beispielsweise Software-Werkzeuge und Werkstoffmodelle zur Analyse und Simulation. Unser Konsortium besteht aus drei divers aufgestellten Fraunhofer-Instituten. Zusammen können wir schon einiges abdecken.
nach oben
 Fraunhofer-Institut für Werkstoffmechanik IWM
Fraunhofer-Institut für Werkstoffmechanik IWM